[Self Notes and Review]:
This is a second writeup in the series of reading DDIA book and publishing my notes from the book.
The first one can be found here
This particular article is from the second chapter of the book. Again, these are just my self notes/extracts and treat this more like an overview/summary. Best way is to read the book in itself.
This chapter dwells in to the details of: the format in which we write data to databases and mechanism by which we read it back.
First - a few terminologies:
-
Relational Database - which has rows and columns and a schema for all the data
- Eg: SQL
-
Non-Relational Database - also known as Document model , Nosql etc , targeting the use case of data comes in self-contained documents and relation between one document to other are rare.
- Eg: Mongo, where the data is stored as a single entity like json object in Mongo
-
Graph Database - where all the data is stored as a vertex and edge, targeting the use case of anything is potentially related to everything.
- Eg: Neo4j, Titan, and InfiniteGraph
-
Imperative language - in an Imperative language like a programming language, you tell the compute
**_what to do_**and**_how to do_**. Like, get the data and go over the loop twice in a particular order etc -
Declarative language - in Declarative query language like SQL used for retrieving data from database, you know tell it
**_what to do_**- andhow to dois decided by the query optimizer.
Relational Model(RDBMS) vs Document Model
-
SQL is the best know RDBMS which has lasted for over 30years.
-
NOSQL - is more of an opposite of RDBMS. And sadly the name “nosql” doesn’t actually refer to any particular technology. It is more of a blanket terms for all non-relational databases.
-
Advantages of Document (Nosql) over Relational (RDBMS) type databases:
-
Ease to scale out in no sql like mongo, where you can add more shards - but in sql type database (relational rdbms type) - they are designed more to scale vertically.
-
ability to store unstructured, semi structured or structured data in nosql - while in rdbms you can store only structured data
-
Ease of updating schema in no sql - like in mongo you can insert docs with new field and it will work just fine
-
you can do blue green deployment in nosql by updating one cluster at a time, but in nosql - you have to take down the system
-
-
Disadvantages of Document (Nosql) over Relational (RDBMS) type databases
-
you cannot directly pick a value from a nested json in document db(you need nested references). In Relation db, you can pick a specific value from its column and row criteria.
-
The poor support for joins in document databases may or may not be a problem, depending on the application.
-
[Use-case]: Relational vs Document models for implementing linkedin design:
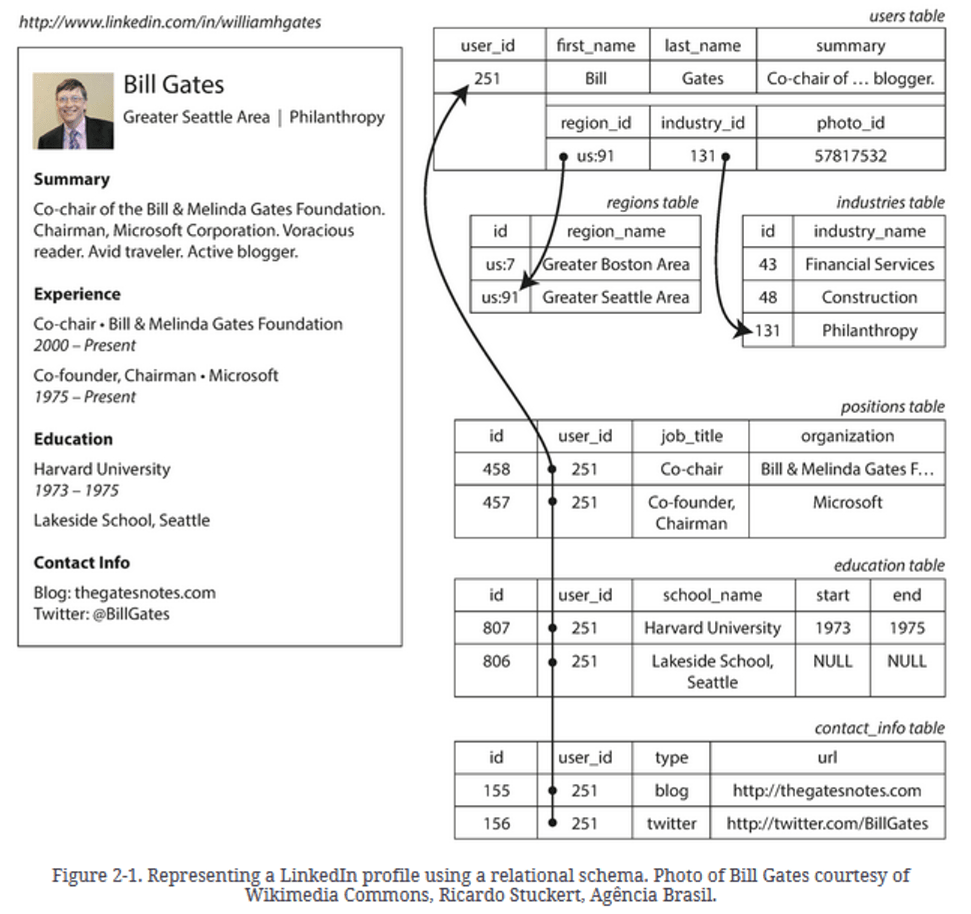
Source : DDIA
-
Relational Model
-
in a relational model like SQL - many
user_idcan be used as an unique identifier across multiple tables -
regionandindustriesare common tables which can be used for different users -
IMPORTANT : in the above example -
users tablehasregion_idandindustry_id- i.e, it has an id and not the common free text.-
This helps maintain consistency and avoid ambiguity/duplications.
Greater Boston Areawill have a single id and the same will be used for all the profiles that match it. -
This also helps updating cases, in which case you will have to update only one place (
regions table) and the same will take effect for all users. -
The advantage of using an ID is that because it has no meaning to humans, it never needs to change: the ID can remain the same, even if the information it identifies changes. Anything that is meaningful to humans may need to change sometime in the future
-
“Unfortunately, normalizing this data requires many-to-one relationships (many people live in one particular region, many people work in one particular industry), which don’t fit nicely into the document model. In relational databases, it’s normal to refer to rows in other tables by ID, because joins are easy. In document databases, joins are not needed for one-to-many tree structures, and support for joins is often weak”
-
On Document db(nosql), we don’t strongly support joins, you will have to pull all the data to the application and do post processing of joins within the application. This can be expensive some times.
-
-
-
Document model
{
"user_id": 251,
"first_name": "Bill",
"last_name": "Gates",
"summary": "Co-chair of the Bill & Melinda Gates... Active blogger.",
"region_id": "us:91",
"industry_id": 131,
"photo_url": "/p/7/000/253/05b/308dd6e.jpg",
"positions": [
{"job_title": "Co-chair", "organization": "Bill & Melinda Gates Foundation"},
{"job_title": "Co-founder, Chairman", "organization": "Microsoft"}
],
"education": [
{"school_name": "Harvard University", "start": 1973, "end": 1975},
{"school_name": "Lakeside School, Seattle", "start": null, "end": null}
],
"contact_info": {
"blog": "https://www.gatesnotes.com/",
"twitter": "https://twitter.com/BillGates"
}
}
- Details on Document model:
-
a self contained document created in json format for the same schema detailed in above section and stored as a single entity
-
the lack of schema in document model makes it easy to handle data in application layer
-
document db follows a
one to manyrelation model for the data of a user - where all the details of the user is present in the same object locally in a tree structure. -
In document db, an object is read completely at once. If the size of each object is very large, it is counter productive. So it is recommended to keep the objects small and avoid write to the same objects which will increase its size.
-
Query Optimizer:
-
Query Optimizer : When you fire a query which has multiple parts - where clause, from clause etc, the query optimizer decides which part to execute first in the most optimized way. These choices are called “access paths” which are decided by query optimizer. A developer will not have to worry about the access path as they are decided automatically. When a new index is introduced, the query optimizer makes a decision on if using it will be helpful, and takes that path automatically.
-
The sql doesn’t guarantee the results in any particular order. “The fact that SQL is more limited in functionality gives the database much more room for automatic optimizations.”
Schema Flexibility:
-
in case of document db although they are called schemaless, that only means, there is an implicit schema for the data, just that it is not enforced by the db.
-
more like
schema on readis maintained, rather thanschema on write- meaning, when you read the data from the db in document db, you expect some kind of structure and the fields to exist on it. -
when the format of the data changes, example: full name has to be split in to
firstnameandlastname- it is much easier on document DB, where the old exists as is, and the new data will have the new field. But in case of Relational database, you will have to perform migration of the schema for pre-existing data.
Graph like Data-models:
-
Disclaimer: I have just skimmed through this section, as I have not directly worked through on Graph model dbs. -
when the data is of the type many-to-many relationship, then modeling data in form of graph makes more sense.
-
Typical examples for graph modeling usecases.
-
Social medias - linking people together.
-
Rail networks
-
Web pages linked to each other
-
-
Structuring data of a couple in a graph like model
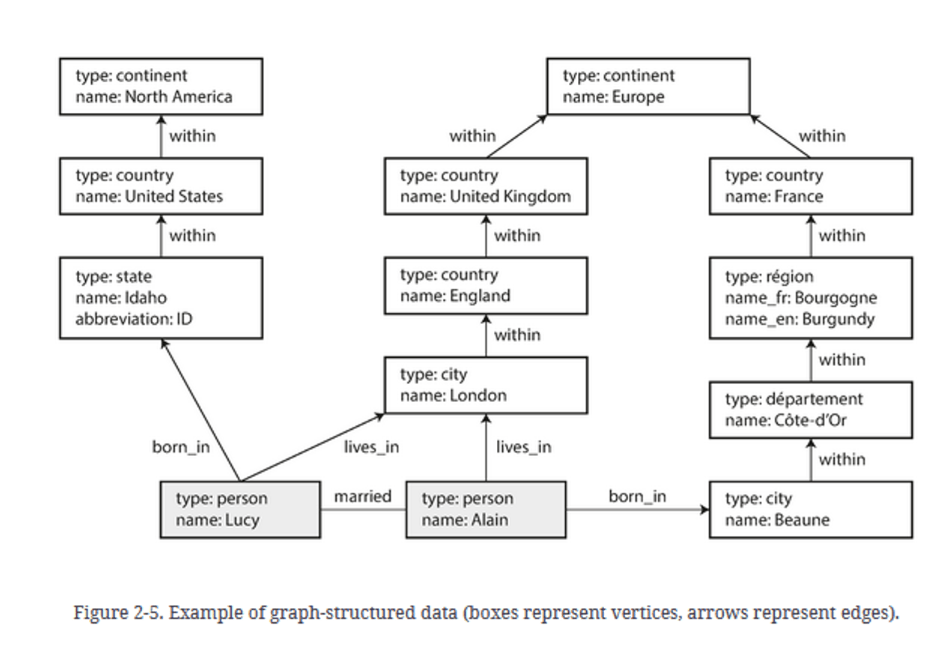
Source: DDIA book
Summary:
-
Historically, data started out being represented as one big tree
-
Then Engineers found that most of the data is related to each other with many-to-many relationship. So Realtion Model (SQL) was invented
-
More recently, developers found that some applications don’t fit well in the relational model either. New nonrelational “NoSQL” datastores have diverged in two main directions:
-
Document databases target use cases where data comes in self-contained documents and relationships between one document and another are rare.
-
Graph databases go in the opposite direction, targeting use cases where anything is potentially related to everything
-
-
All three models (document, relational, and graph) are widely used today, and each is good in its respective domain.
-
One thing that document and graph databases have in common is that they typically don’t enforce a schema for the data they store, which can make it easier to adapt applications to changing requirements
-
Each data model comes with its own query language or framework. Examples: SQL, MapReduce, MongoDB’s aggregation pipeline, Cypher, SPARQL, and Datalog